
Classifying Phone Numbers
11 May, 2015
What an exiting week last week. I was in Chicago for Microsoft Ignite 2015. I had the opportunity to attend several very interesting sessions as well as walk the expo floor and meet with other great people in the PowerShell and Skype for Business community.
You might also notice from the tags above that I’m going to start using the SkypeForBusiness instead of the Lync tag. Both tag pages cross link to each other so in case you end up in one, you’ll have a friendly reminder to check the other as well.
The Inspiration
One of the sessions I attended was called “Save Time! Automate Phone Number Management in Skype for Business” by @StaleHansen. It was a great talk and I encourage you to check it as since it talks about similar topics that I’ve spoken about and it mentions both my Managing Your Lync Phone Numbers and Keeping Lync Unassigned Numbers Updated posts.
In this talk, he spoke about classifying numbers to keep nice numbers for certain use cases (IVRs, main numbers, senior executives, etc). There was an excellent slide that had rules he proposed:
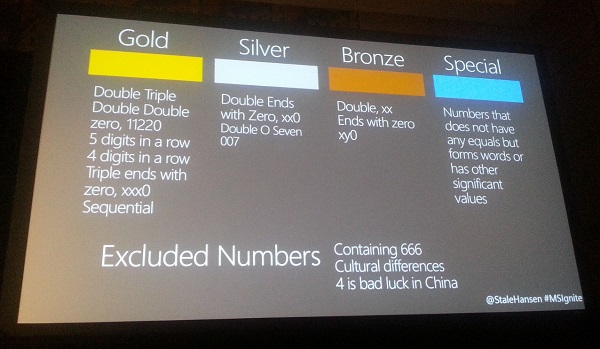
In speak with him afterwards he mentioned that he hadn’t had time yet to implement the classification using regular expressions and I offered to help.
The Regular Expressions
I’ve created the following script to take a number and return a classification of Gold, Silver, Bronze or Ordinary based on his rules plus one more of my own (Silver numbers can have repeated patterns, like ending in 1212). It uses the following regular expressions to classify the numbers
| Class | Reason | RegEx |
|---|---|---|
| Gold | Double Triple | (\d)\1(\d)\2{2}$ |
| Gold | Double Double 0 | (\d)\1(\d)\2{1}0$ |
| Gold | Triple 0 | (\d)\1{2}0$ |
| Gold | Same 4 | (\d)\1{3}$ |
| Gold | Sequential 4 | (?:0(?=1)|1(?=2)|2(?=3)|3(?=4)|4(?=5)|5(?=6)|6(?=7)|7(?=8)|8(?=9)|9(?=0)){3}\d$ |
| Silver | Double 0 | (\d)\1{1}0$ |
| Silver | James Bond | 007$ |
| Silver | Two Digit Pattern | (\d{2})\1$ |
| Bronze | Double | (\d)\1$ |
| Bronze | Ends in 0 | 0$ |
Anything else is classified as Ordinary.
A couple quick notes on the regular expressions:
- $ matches the end of the line
- \d matches any number
- * means match the preceding item 0 or more times
- ? means match the preceding item 0 or 1 times
-
- means match the preceding item 1 or more times
- {#} means match the preceding item exactly # times
- any statement within () creates a capture group with some exceptions
- if the capture group starts with ?: that means don’t capture
- (?x) isn’t a capture group but says the regular expression should ignore comments and unescaped whitespace; this makes large complex expressions more readable
- (?=…) means match as long as the next item matches the group …, but it doesn’t capture this next item
-
groups can have multiple options separated by - \1 (or any \#, etc) matches the 1st (or #th) capture group
You may have noticed that I used {1} in some of the regular expressions. You don’t normally need to do this (the default is to match one), but I do this when I want to match 0 afterwards since I need to break up the numbers, otherwise if I wrote (\d)\10 (for example) it would want to match a digit followed by the value of the 10th capture group. This could be written other ways, like (\d)\1[0] or (\d)\1(?:0) or even (\d)\1 0 (if you’re using (?x)), all of which are identical.
The Complicated One
The Sequential 4 is probably the most complex so I’ll take a moment to describe it.
(?:
0(?=1)| # match a 0 as long as a 1 comes after
1(?=2)| # match a 1 as long as a 2 comes after
2(?=3)| # match a 2 as long as a 3 comes after
3(?=4)| # match a 3 as long as a 4 comes after
4(?=5)| # match a 4 as long as a 5 comes after
5(?=6)| # match a 5 as long as a 6 comes after
6(?=7)| # match a 6 as long as a 7 comes after
7(?=8)| # match a 7 as long as a 8 comes after
8(?=9)| # match a 8 as long as a 9 comes after
9(?=0) # match a 9 as long as a 0 comes after
){3} # do that 3 times
\d # and also capture the last digit
So the only way for it to be able to capture a 2 (for example) is if a 3 comes next. If that’s the case then it would also match the 3, but only if a 4 came next, and so on. It has to do this 3 times, which means there have to be 4 sequential numbers. Because the look forward ?= doesn’t capture that digit it ensured was there, I’ve included a \d at the end to capture it.
Slow and Fast
Some of these regular expressions are a little complex so I’ve implemented it two ways so that people can see different ways it could be done.
The first way is using an array simple regular expressions that are tested one after another.
$CLASSES = @{
Gold = @{
doubleTriple = "(\d)\1(\d)\2{2}$";
doubleDouble0 = "(\d)\1(\d)\2{1}0$";
triple0 = "(\d)\1{2}0$";
same4 = "(\d)\1{3}$";
sequential4 = "(?:0(?=1)|1(?=2)|2(?=3)|3(?=4)|4(?=5)|5(?=6)|6(?=7)|7(?=8)|8(?=9)|9(?=0)){3}\d$"
};
Silver = @{
double0 = "(\d)\1{1}0$";
bond = "007$";
twoDigitPattern = "(\d{2})\1$"
};
Bronze = @{
double = "(\d)\1$";
endsIn0 = "0$"
}
}
function ClassifySlow($number) {
Write-Verbose "Classifying $number (slow)"
$class = "Ordinary"
$reason = ""
foreach($c in @("Gold","Silver","Bronze")) {
$CLASSES[$c].GetEnumerator() | foreach {
if($number -match $_.Value) {
$class = $c
$reason = $_.Key
break
}
}
}
@{Number = $number; Class = $class; Reason = $reason}
}
The second is by combining all of the regular expressions together and allowing the regular expression engine to optimize the parsing.
$CLASS_RE = "(?x)
(?:
(?<Gold_doubleTriple>(\d)\1(\d)\2{2})
|
(?<Gold_doubleDouble0>(\d)\3(\d)\4 0)
|
(?<Gold_triple0>(\d)\5{2}0)
|
(?<Gold_same4>(\d)\6{3})
|
(?<Gold_sequential4>(?:0(?=1)|1(?=2)|2(?=3)|3(?=4)|4(?=5)|5(?=6)|6(?=7)|7(?=8)|8(?=9)|9(?=0)){3}\d)
|
(?<Silver_double0>(\d)\7 0)
|
(?<Silver_bond>007)
|
(?<Silver_twoDigitPattern>(\d{2})\8)
|
(?<Bronze_double>(\d)\9)
|
(?<Bronze_endsIn0>0)
)$"
function ClassifyFast($number) {
Write-Verbose "Classifying $number (fast)"
$class = "Ordinary"
$reason = ""
if($number -match $CLASS_RE) {
$class,$reason = $($matches.Keys | ? { $_ -notmatch "^[0-9]+$" }) -split '_'
}
@{Number = $number; Class = $class; Reason = $reason}
}
Since these two alternate methods are driven by performance, I’ve included a -Test flag you can use to experience the differences between the two. In test runs on my computer, the normal fast option using the combined all-in-one regex runs about 3x faster than the slow option. There are some additional optimizations that make it possible for the slow option to run similar to the fast option but the it requires unwinding the nicely maintainable hash into arrays and using 53 lines instead of 10. Actually the code difference is event larger when you take into consideration that the all-in-one regular expression really is just 2 core lines of if(-match) and finding and splitting out the class and reason from the group capture name.
Coming up next is testing scripts with Pester. If you want a sneak peak, checkout the test script for this script here: Get-PhoneNumberClass.Tests.ps1.